Dataset Configuration
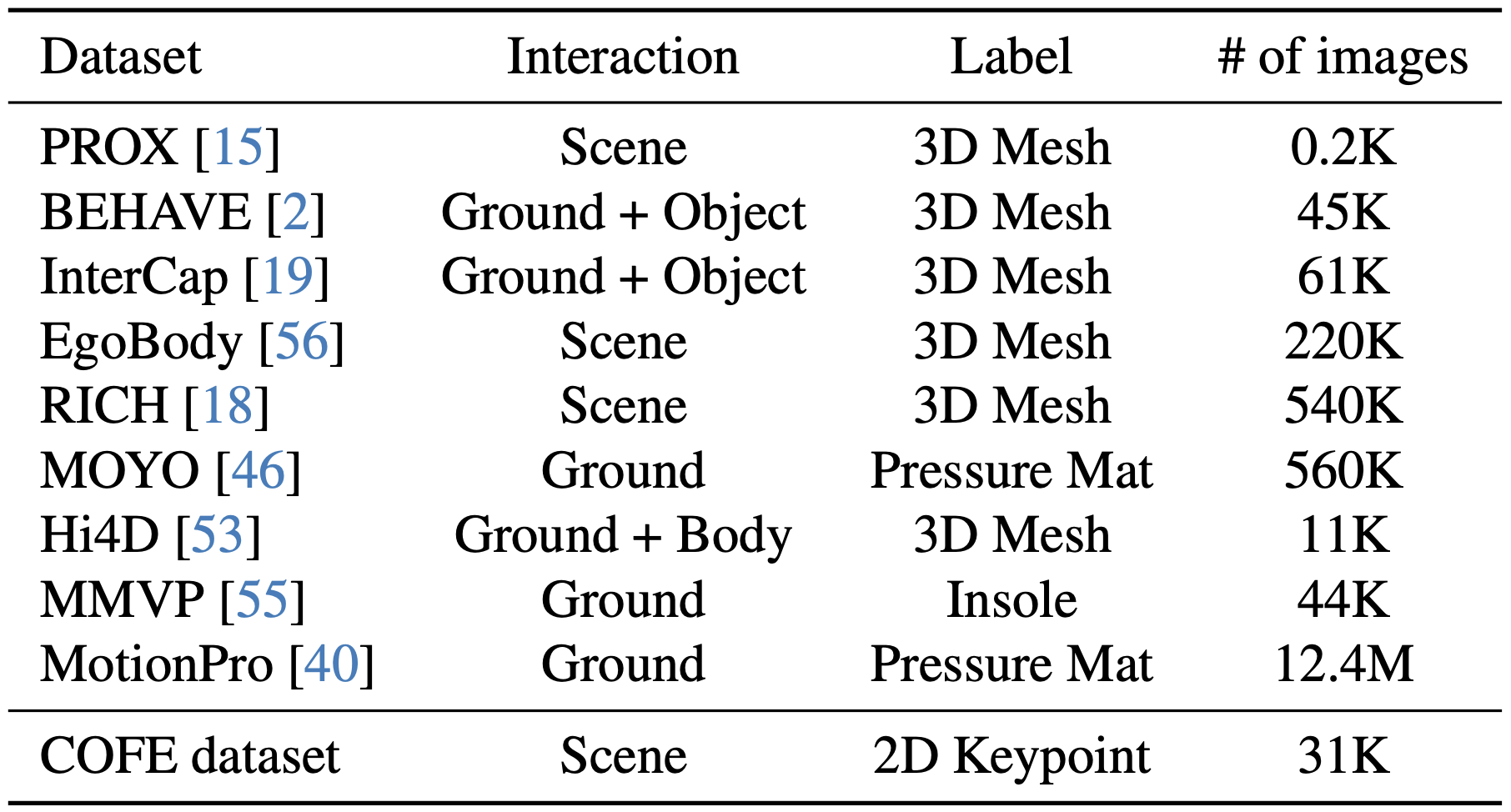
We leverage 10 datasets with various foot interaction, including our proposed COFE dataset that provides in-the-wild joint-level foot contact annotations.
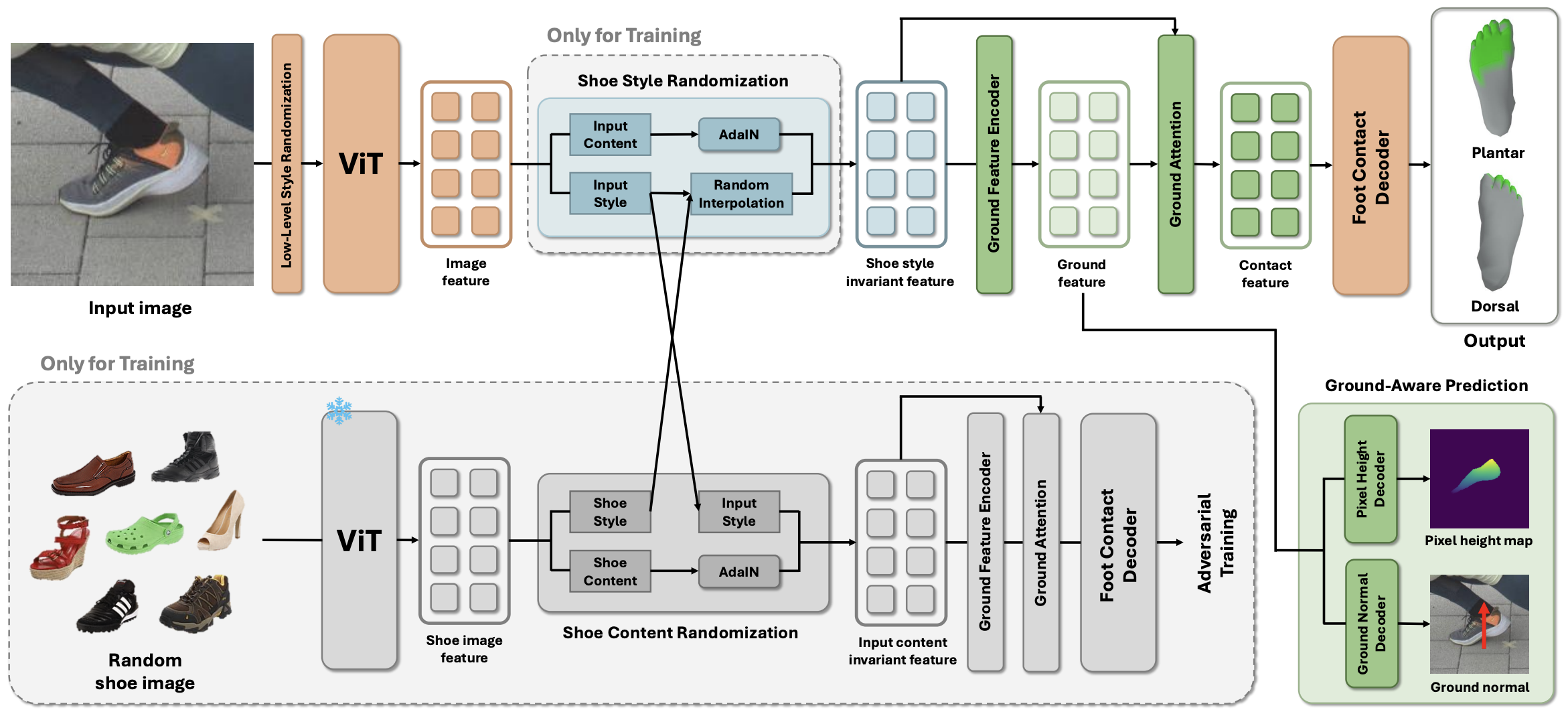
Model Architecture
Our method first applies low-level style randomization on input image and encodes it into image feature using a ViT backbone. From image feature, shoe style and shoe content randomization are performed with random shoe images from the UT Zappos50K dataset to produce a shoe style-invariant feature. This feature is then processed by a ground feature encoder to extract ground feature, which is used to predict pixel height map and ground normal. Finally, the ground feature and shoe style-invariant feature are fused to form a contact feature, which is decoded to produce the final foot contact prediction.
Qualitative Results

Qualitative Results

Related Links
There's a lot of excellent works that we wish to share.
Reducing domain gap by reducing style bias.
Progressive random convolutions for single domain generalization.
DECO: Dense Estimation of 3D Human-Scene Contact In The Wild.
Learning Dense Hand Contact Estimation from Imbalanced Data.